背景
在Google Colab上进行压缩采样的图像重建模型的训练。已经有了训练好的压缩率是0.20的模型(下文用r0.20之类的记号表示压缩率及其对应的模型)。现在想训练r0.25。觉得从头开始训练很费时间于是就想出了这么个办法
checkpoint = torch.load('ResCsNet-colab-5_2_1-r0.20_checkpoint.pth')
model = ResCsNet(N, int(0.20*N))
model.load_state_dict(checkpoint['state_dict'])
model = model_r20
model.encoder = model_r25.encoder我的模型大致分为编码器和解码器两部分。编码器可以直接通过.encoder访问。上面这段代码的意思是从r0.20中载入所有训练参数,然后把编码器部分换成r0.25的编码器。刚开始的时候r0.25编码器参数是随机初始化的。
过程
一开始训练并不能察觉到什么异样(如图)

因为Colab每隔12h就会重置虚拟机,因此过了12h后接着训练必须重新载入之前保存的训练参数。我直接保存的是model的参数:
state = {
'tfx_steps': tfx_steps,
'tfx_epochs_done': tfx_epochs_done,
'state_dict': <strong>model</strong>.state_dict(),
'optimizer' : optimizer.state_dict(),
'lr_scheduler': lr_scheduler.state_dict()
}
torch.save(state, ckpt_name)问题是直接载入这保存的参数会出问题!
checkpoint = torch.load(fname)
tfx_steps = checkpoint['tfx_steps']
print(f"tfx_steps is {tfx_steps}")
tfx_epochs_done = checkpoint['tfx_epochs_done']
print(f"tfx_epochs_done is {tfx_epochs_done}")
model = ResCsNet(N, int(0,25*N))
model.load_state_dict(checkpoint['state_dict'])
model.train()
model.cuda()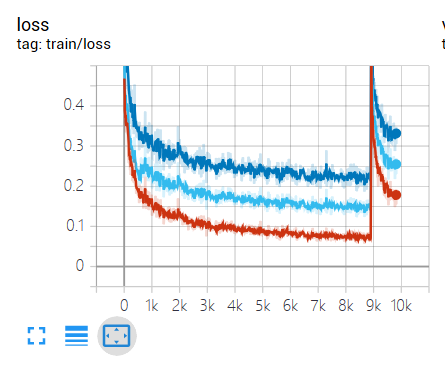
一个很显而易见的事情是:从checkpoint文件里重新加载的模型(包块optimizer也加载了),其参数居然向没训练过似的(如上图突然上跳的loss曲线)。虽然并不明白为什么但是很显然着跟之前“拼接”训练模型这个动作有关。
正确的做法的探讨
正确的做法似乎(我没有验证)是:(正如 https://pytorch.org/tutorials/beginner/saving_loading_models.html#warmstarting-model-using-parameters-from-a-different-model 介绍的那样)
modelB = TheModelBClass(*args, **kwargs) modelB.load_state_dict(torch.load(PATH), strict=False)
也就是
# 一开始的时候就应该这么做吧
model_r25 = ResCsNet(N, int(0.25*N))
model_r20 = ResCsNet(N, int(0.20*N))
model_r20_state_dict = torch.load('ResCsNet-colab-5_2_1-r0.20_checkpoint.pth')['state_dict']
model = ResCsNet(N, int(0.25*N))
model.load_state_dict(model_r20_state_dict, strict=False)
model.encoder.load_state_dict( model_r25.encoder.state_dict() )
tutorial声称strict=False参数能够允许不匹配的键名,当然改键名(https://stackoverflow.com/questions/16475384/rename-a-dictionary-key)也是可以的。